
Machine Learning et Big Data : définition et explications
Le Machine Learning est une technologie d’intelligence artificielle permettant aux ordinateurs d’apprendre sans avoir été programmés explicitement à cet effet. Pour apprendre et se développer, les ordinateurs ont toutefois besoin de données à analyser et sur lesquelles s’entraîner. De fait, le Big Data est l’essence du Machine Learning, et c’est la technologie qui permet d’exploiter pleinement le potentiel du Big Data. Découvrez pourquoi cette technique et le Big Data sont interdépendants.
Apprentissage automatique définition : qu’est-ce que le Machine Learning ?
Si le Machine Learning ne date pas d’hier, sa définition précise demeure encore confuse pour de nombreuses personnes. Concrètement, il s’agit d’une science moderne permettant de découvrir des patterns et d’effectuer des prédictions à partir de données en se basant sur des statistiques, sur du forage de données, sur la reconnaissance de patterns et sur les analyses prédictives. Les premiers algorithmes sont créés à la fin des années 1950. Le plus connu d’entre eux n’est autre que le Perceptron.
Le Machine Learning est très efficace dans les situations où les insights doivent être découvertes à partir de larges ensembles de données diverses et changeantes, c’est à dire : le Big Data. Pour l’analyse de telles données, il se révèle nettement plus efficace que les méthodes traditionnelles en termes de précision et de vitesse. Ainsi, cette méthode est nettement plus efficace que les méthodes traditionnelles pour l’analyse de données transactionnelles, de données issues des réseaux sociaux ou de plateformes CRM.
Machine Learning et Big Data : pourquoi utiliser le Machine Learning avec le Big Data ?
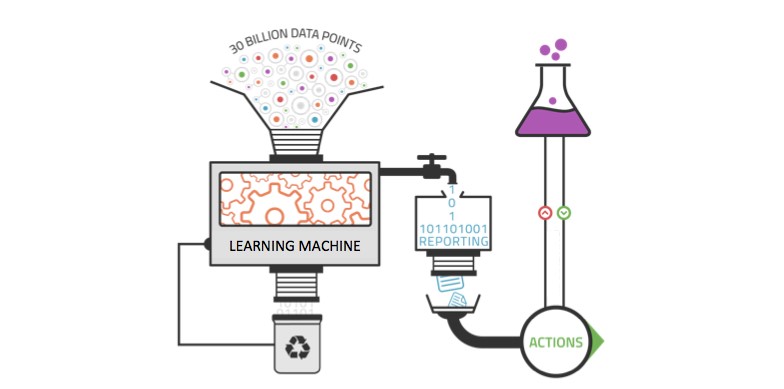
Les outils analytiques traditionnels ne sont pas suffisamment performants pour exploiter pleinement la valeur du Big Data. Le volume de données est trop large pour des analyses compréhensives, et les corrélations et relations entre ces données sont trop importantes pour que les analystes puissent tester toutes les hypothèses afin de dégager une valeur de ces données.
Les méthodes analytiques basiques sont utilisées par les outils de business intelligence et de reporting pour le rapport des sommes, pour faire les comptes et pour effectuer des requêtes SQL. Les traitements analytiques en ligne sont une extension systématisée de ces outils analytiques basiques qui nécessitent l’intervention d’un humain pour spécifier ce qui doit être calculé.
Comment ça marche ?
Le Machine Learning est idéal pour exploiter les opportunités cachées du Big Data. Cette technologie permet d’extraire de la valeur en provenance de sources de données massives et variées sans avoir besoin de compter sur un humain. Elle est dirigée par les données, et convient à la complexité des immenses sources de données du Big Data. Contrairement aux outils analytiques traditionnels, il peut également être appliqué aux ensembles de données croissants. Plus les données injectées à un système Machine Learning sont nombreuses, plus ce système peut apprendre et appliquer les résultats à des insights de qualité supérieure. Le Machine Learning permet ainsi de découvrir les patterns enfouis dans les données avec plus d’efficacité que l’intelligence humaine.
Machine Learning et Big Data : les analyses prédictives donnent du sens au Big Data

Les analyses prédictives consistent à utiliser les données, les algorithmes statistiques et les techniques de Machine Learning pour prédire les probabilités de tendances et de résultats financiers des entreprises, en se basant sur le passé.
Elles rassemblent plusieurs technologies et disciplines comme les analyses statistiques, le data mining, le modelling prédictif et le Machine Learning pour prédire le futur des entreprises. Par exemple, il est possible d’anticiper les conséquences d’une décision ou les réactions des consommateurs.
Les analyses prédictives permettent de produire des insights exploitables à partir de larges ensembles de données, pour permettre aux entreprises de décider quelle direction emprunter par la suite et offrir une meilleure expérience aux clients.
Grâce à l’augmentation du nombre de données, de la puissance informatique, et du développement de logiciels IA et d’outils analytiques plus simples à utiliser, comme Salesforce Einstein, un grand nombre d’entreprises peuvent désormais utiliser les analyses prédictives.
L’intelligence artificielle et le Machine Learning représentent le niveau supérieur des analyses de données. Les systèmes informatiques cognitifs apprennent constamment sur l’entreprise et prédisent intelligemment les tendances de l’industrie, les besoins des consommateurs et bien plus encore.
Peu d’entreprises ont déjà atteint le niveau des applications cognitives, défini par quatre caractéristiques principales : la compréhension des données non structurées, la possibilité de raisonner et d’extraire des idées, la capacité à affiner l’expertise à chaque interaction, et la capacité à voir, parler et entendre pour interagir avec les humains de façon naturelle. Pour cela, il convient de développer le traitement par algorithme des langages naturels.
Machine Learning et Big Data : l’apprentissage automatique au service du Data Management

Face à l’augmentation massive du volume de données stockées par les entreprises, ces dernières doivent faire face à de nouveaux défis. Parmi les principaux challenges liés au Big Data, on dénombre la compréhension du « Dark Data », la rétention de données, l’intégration de données pour de meilleurs résultats analytiques, et l’accessibilité aux données. Le Machine Learning peut s’avérer très utile pour relever ces différents défis.
Toutes les entreprises accumulent au fil du temps de grandes quantités de données qui demeurent inutilisées. Il s’agit des « Dark Data ». Grâce au Machine Learning et aux différents algorithmes, il est possible de faire le tri parmi ces différents types de données stockées sur les serveurs. Par la suite, un humain qualifié peut passer en revue le schéma de classification suggéré par l’intelligence artificielle, y apporter les changements nécessaires, et le mettre en place.
Pour la rétention de données, cette pratique peut également s’avérer efficace. L’intelligence artificielle peut identifier les données qui ne sont pas utilisées et suggérer lesquelles peuvent être supprimées. Même si les algorithmes n’ont pas la même capacité de discernement que les êtres humains, le Machine Learning permet de faire un premier tri dans les données. Ainsi, les employés économisent un temps précieux avant de procéder à la suppression définitive des données obsolètes.
Cette technologie est aussi utile pour l’intégration de données. Pour tenter de déterminer le type de données qu’ils doivent agréger pour leurs requêtes, les analystes créent généralement un répertoire dans lequel ils placent différents types de données en provenance de sources variées pour créer un bassin de données analytique. Pour ce faire, il est nécessaire de développer des méthodes d’intégration pour accéder aux différentes sources de données en provenance desquelles ils extraient les données. Cette technique peut faciliter le processus en créant des mappings entre les sources de données et le répertoire. Ceci permet de réduire le temps d’intégration et d’agrégation.
Enfin, l’apprentissage des données permet d’organiser le stockage de données pour un meilleur accès. Au cours des cinq dernières années, les vendeurs de solutions de stockage de données ont mis leurs efforts dans l’automatisation de la gestion de stockage. Grâce à la réduction de prix du SSD, ces avancées technologiques permettent aux départements informatiques d’utiliser des moteurs de stockage intelligents reposant sur le machine Learning pour voir quels types de données sont utilisés le plus souvent et lesquels ne sont pratiquement jamais utilisé. L’automatisation peut être utilisée pour stocker les données en fonction des algorithmes. Ainsi, l’optimisation n’a pas besoin d’être effectuée manuellement.